A Neuromorphic Machine Learning Framework based on the Growth Transform Dynamical System
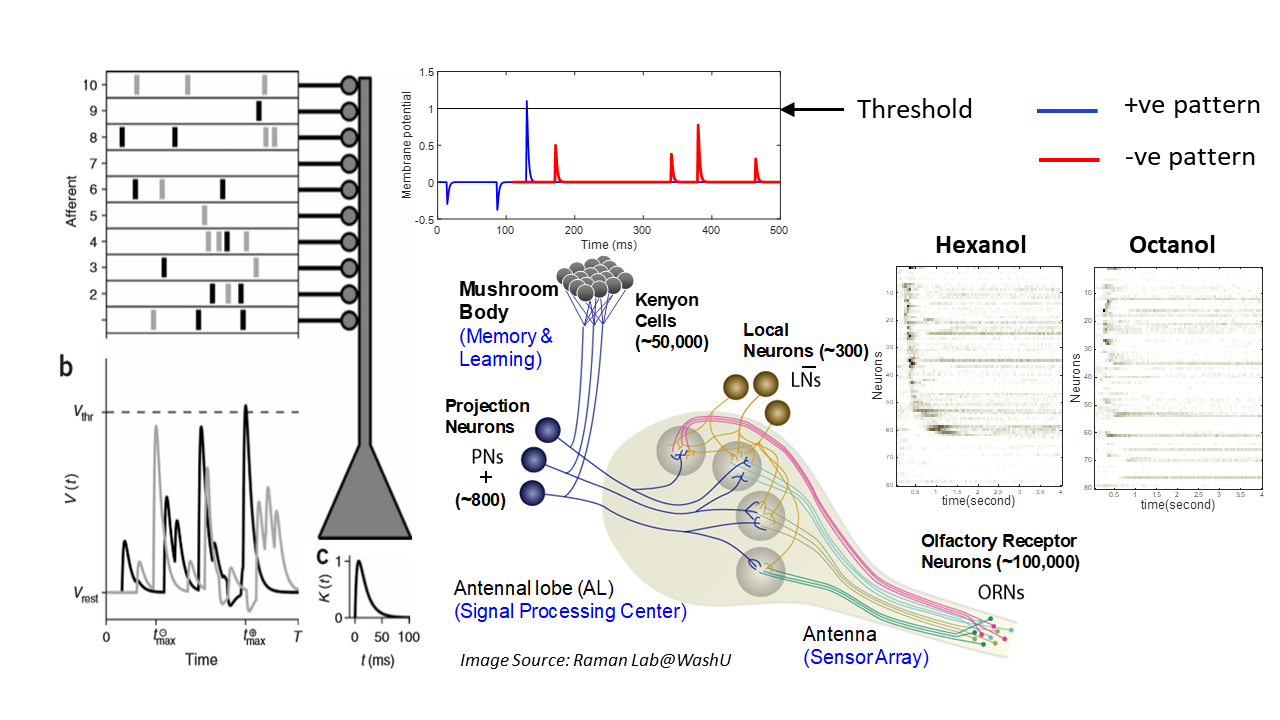
In neuromorphic machine learning, neural networks are designed in a bottom-up fashion - starting with the model of a single neuron and connecting them together to form a network. Although these spiking neural networks use biologically relevant neural dynamics and learning rules, they are not optimized w.r.t. a network objective.
In contrast in traditional machine learning, neural networks are designed in a top-down manner, starting from a network objective (loss function), and reducing it to adjust the parameters of a non-spiking neuron model with static nonlinearities. Although these are highly optimized w.r.t. a network objective (usually a training error), they do not produce biologically relevant neural dynamics - potentially losing out on the performance and energy benefits of biological systems.
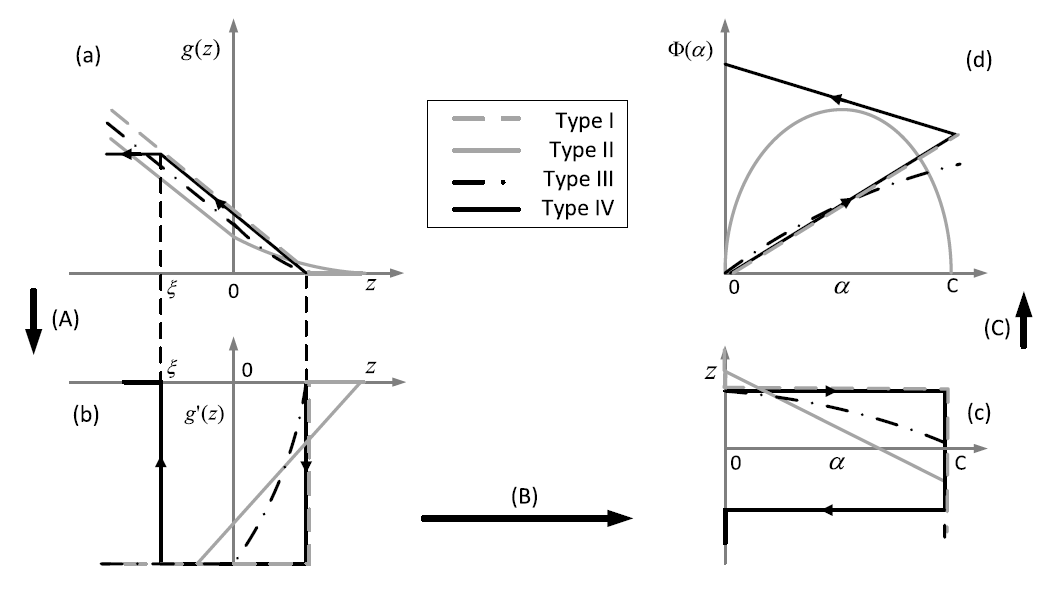
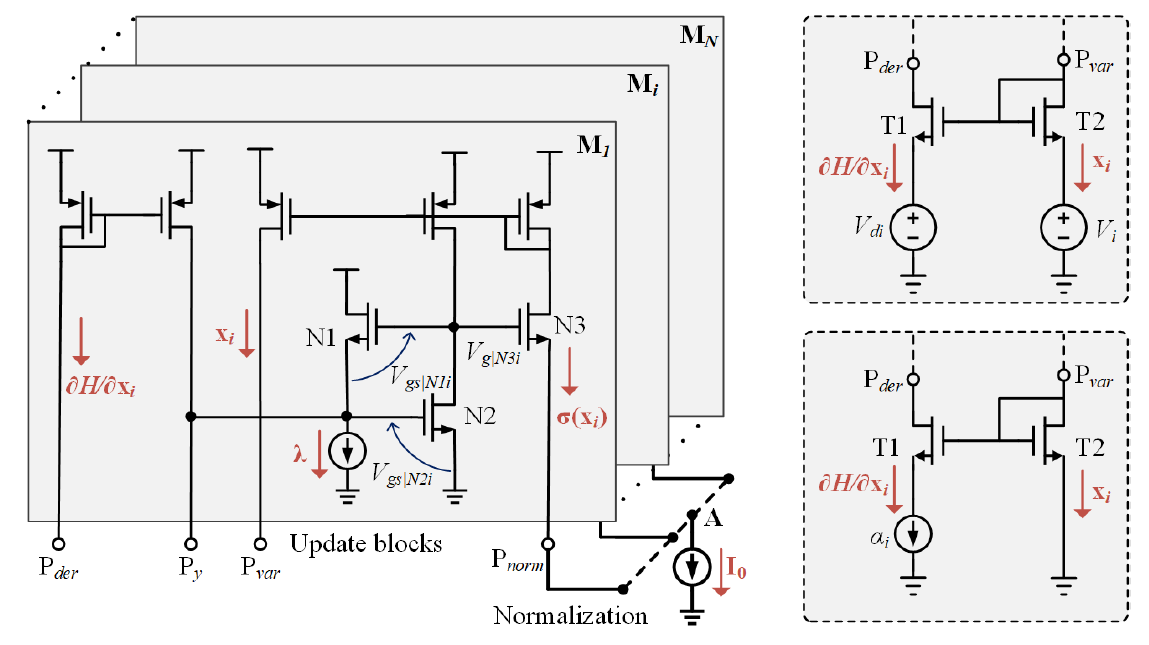
We developed a spiking neuron and population model that reconciles the top-down and bottom-up approaches to achieve the best of both worlds. The dynamical and spiking responses of the neurons are derived by directly minimizing a network objective function under realistic physical constraints using Growth Transforms. The model exhibits several single-neuron response characteristics and population dynamics as seen in biological neurons. We are currently working on designing new scalable learning algorithms for the spiking neuron model for cognitive applications.